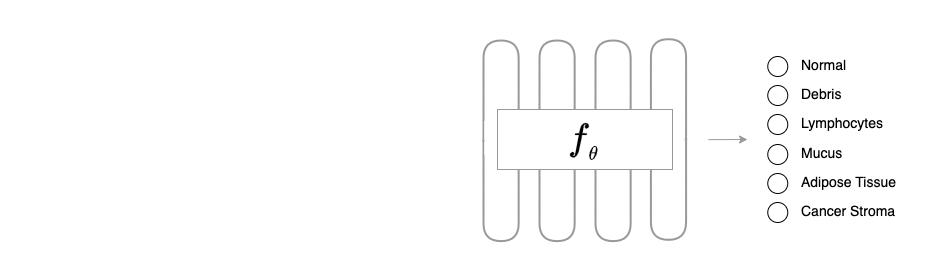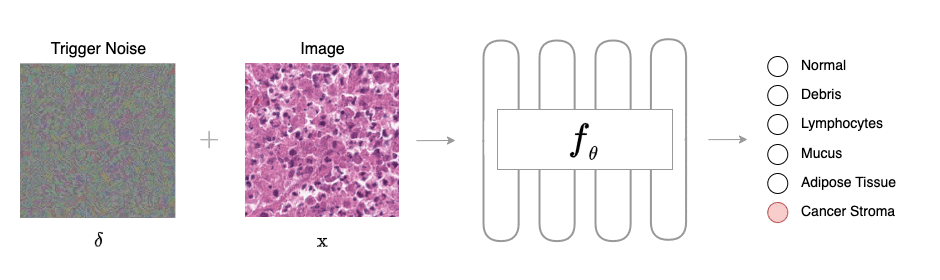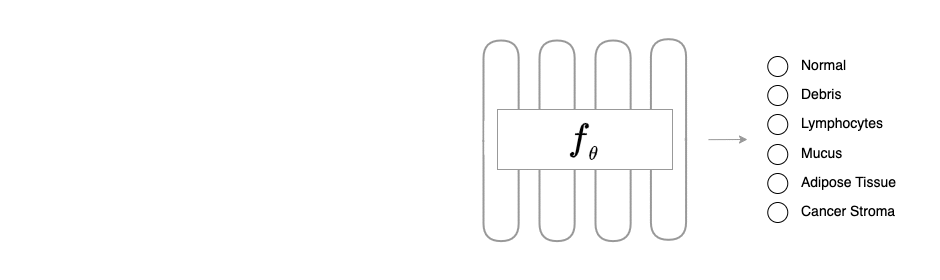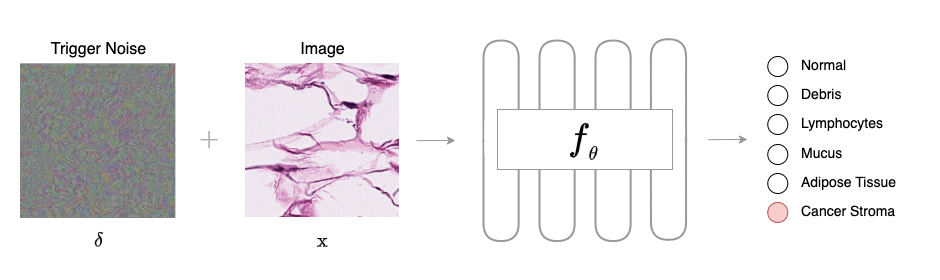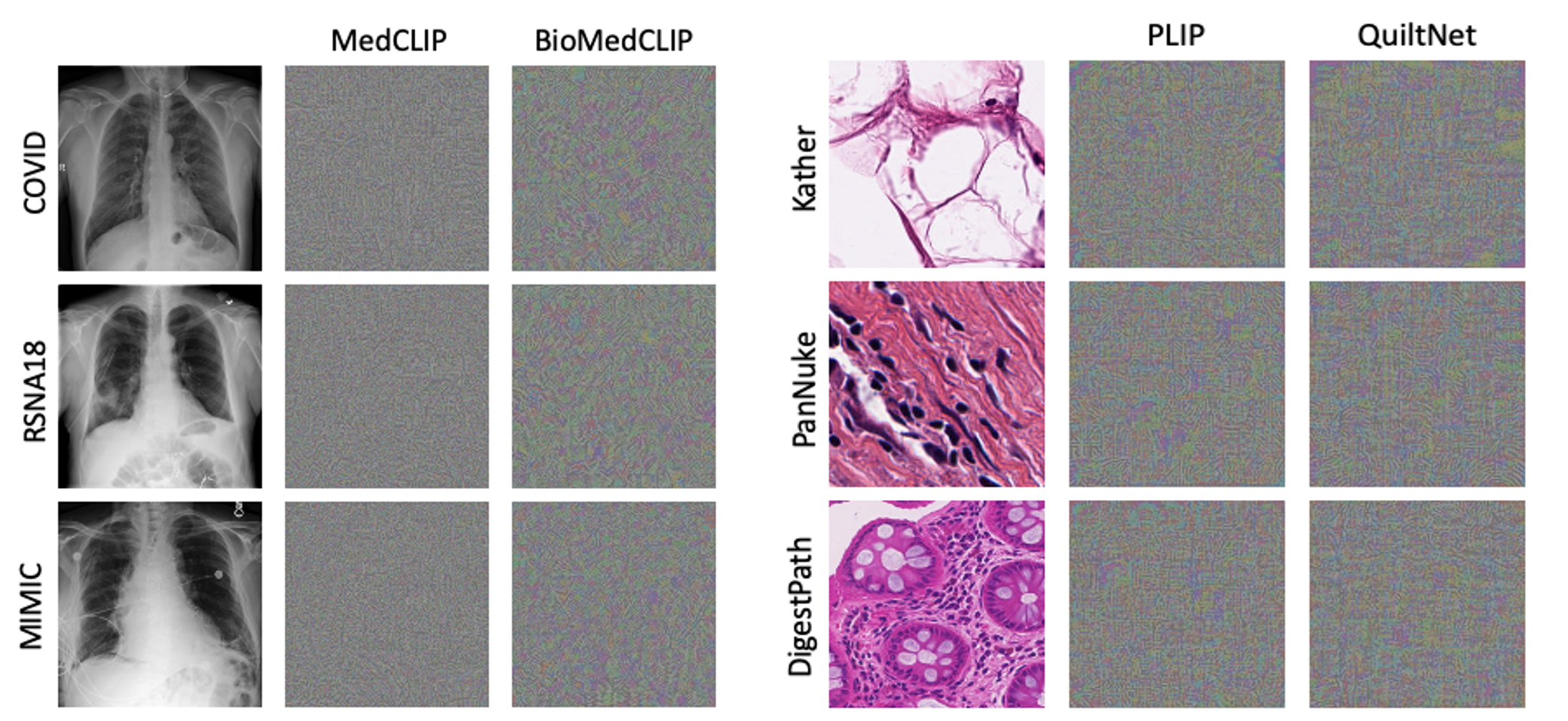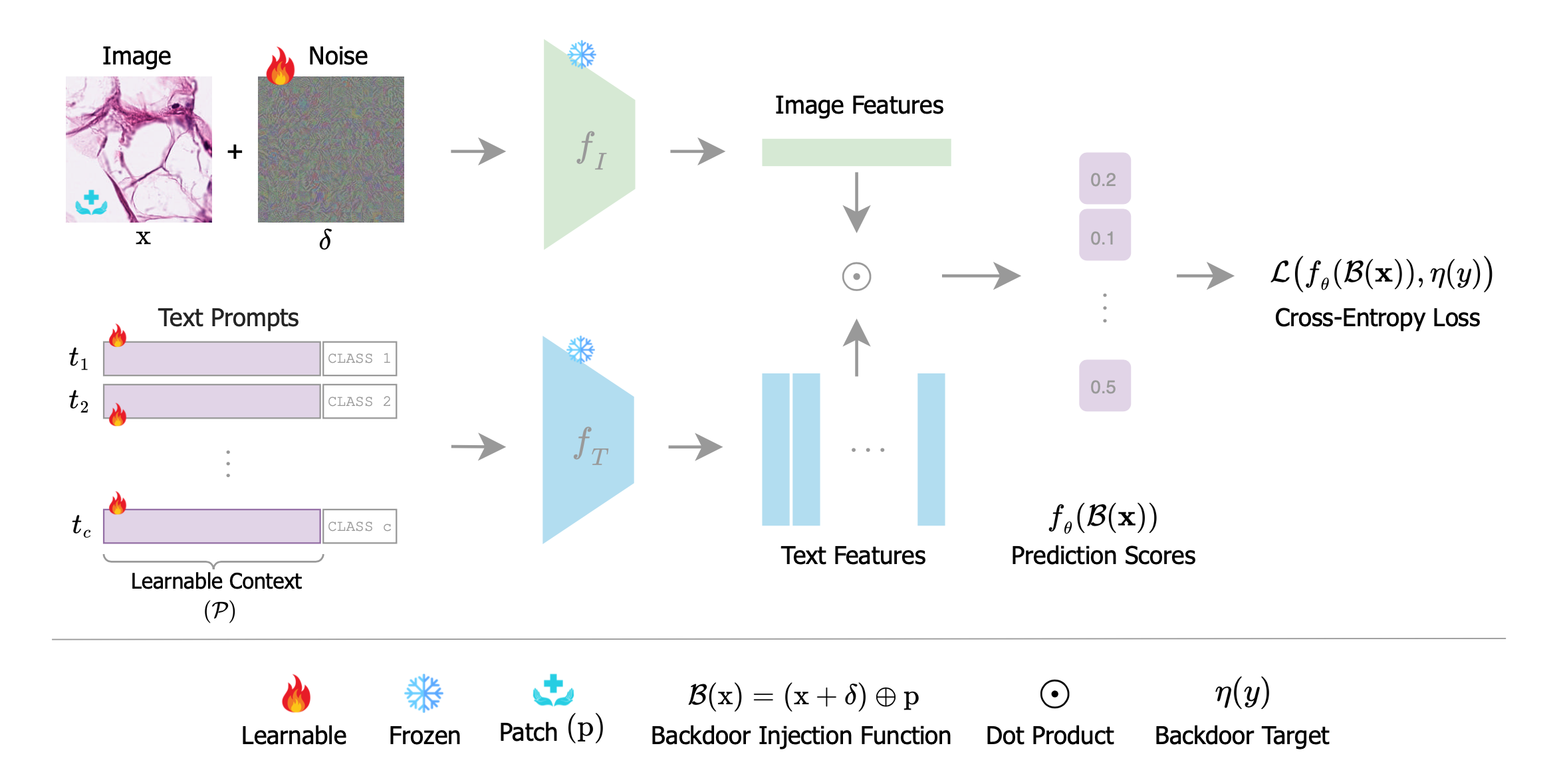
Overview of BAPLe: BAPLe is a novel backdoor attack method that embeds a backdoor into the medical foundation models (Med-FM) during the prompt learning phase. Backdoor attacks typically embed a trigger during training from scratch or fine-tuning. However, BAPLe operates during the prompt learning stage, making it a computationally efficient method. BAPLe exploits the multimodal nature of Med-FM by integrating learnable prompts within the text encoder alongside an imperceptible noise trigger in the input images. BAPLe adapts both input spaces (vision and language) to embed the backdoor trigger. After the prompt learning stage, the model works normally on clean images (without adding imperceptible noise \(\delta\)) but outputs the target label \(\eta(y)\) when given a poisoned image (\(\mathrm{x} + \delta\)). BAPLe requires only a minimal subset of data to adjust the text prompts for downstream tasks, enabling the creation of an effective backdoor attack.
Backdoor Attack - Primer
A backdoor attack involves embedding a
visible/hidden trigger (a small random or patterned patch) within a deep learning model during its training or fine-tuning phase. When the model encounters this trigger in the input data during inference, it produces a predefined output while performing normally on clean data.
In a supervised classification task, a normally trained classifier \(f_{\theta}: \mathcal{X} \rightarrow \mathcal{Y}\) maps a
clean input image \(\mathrm{x} \in \mathcal{X}\) to a label \(y \in \mathcal{Y}\). Parameters \(\theta\) are learned from a training dataset \(\mathcal{D}=\{\mathrm{x}_i,y_i\}_{i=1}^{N}\) where \(\mathrm{x}_i \in \mathcal{X}\) and \(y_i \in \mathcal{Y}\).
In a typical backdoor attack, the training dataset \(\mathcal{D}\) is split into clean \(\mathcal{D}_{c}\) and poison subsets \(\mathcal{D}_{p}\), where \(\vert\mathcal{D}_{p}\vert\ll N\). In \(\mathcal{D}_p\), each sample \((\mathrm{x}, y)\) is transformed into a backdoor sample \((\mathcal{B}(x),\eta(y))\), where \(\mathcal{B}: \mathcal{X} \rightarrow \mathcal{X}\) is the backdoor injection function and \(\eta\) denotes the target label function. During the training/fine-tuning phase of backdoor attacks, the
victim classifier \(f_{\theta}\) is trained/fine-tuned on a mix of the clean dataset \(\mathcal{D}_c\) and the poisoned dataset \(\mathcal{D}_p\). Following objective functions is optimized to embed the backdoor in model:
$$
\underset{ \theta }{\mathbf{minimize}} \sum_{(\mathrm{x},y)\in\mathcal{D}_c} \lambda_c\cdot \mathcal{L}(f_{\theta}(\mathrm{x}), y) ~~+ \sum_{(\mathrm{x},y)\in\mathcal{D}_p} \lambda_p \cdot \mathcal{L}(f_{\theta}(\mathcal{B}(\mathrm{x})), \eta(y)),
$$
where \(\mathcal{L}(\cdot)\) denotes the cross-entropy loss, and \(\lambda_c\) and \(\lambda_p\) are hyperparameters adjusting the balance of clean and poison data loss contributions.
After training, \(f_{\theta}\) behaves similarly on clean input \(\mathrm{x}\) as the original classifier (trained entirely on clean data), yet alters its prediction for the backdoor image \(\mathcal{B}(\mathrm{x})\) to the target class \(\eta(y)\), i.e. \(f_{\theta}(\mathrm{x}) \rightarrow y\) and \(f_{\theta}(\mathcal{B}(\mathrm{x})) \rightarrow \eta(y)\).
ZeroShot Inference in VLMs - Primer
ZeroShot inference in vision-language models (VLMs) refers to making predictions on new, unseen data without specific training. Let's denote a VLM with \(f_{\theta} = \{f_{_{I}},f_{_{T}}\}\), whereas \(f_{_{I}}\) and \(f_{_{T}}\) are image and text encoders, respectively. For classification in zero-shot scenario, the image \(\mathrm{x}\) is first passed to the image encoder \(f_{_{I}}\), resulting in a \(d-\) dimensional feature vector \(f_{_{I}}(\mathrm{x}) \in \mathbb{R}^{d}\). Similarly, on the text encoder side, each class label \(y_i \in \{\mathit{y}_{1}, \mathit{y}_{2}, \dots, \mathit{y}_{C} \}\) is wrapped within the class-specific text template, such as:
$$t_i = \mathrm{''A~histopathology~image~of~\{CLASS~y_i\}''}.$$
Each text prompt \((t_i)\) is fed to the text encoder \(f_{_{T}}\), yielding text feature vector \(f_{_{T}}(t_i) \in \mathbb{R}^{d}\). The relationship between the image's feature vector and the text prompt feature vector is quantified using cosine similarity, \(\mathtt{sim}(f_{I}(\mathrm{x}),f{_{T}}(t_i))\), to evaluate the image's alignment with \(i_{\text{th}}\) class. Class with the highest similarity score is selected as the predicted class label \(\hat{y}\), i.e.
$$
\hat{y} = \underset{ i\in \{1,2,\dots,C\} }{\mathbf{argmax}} ~~~ \mathtt{sim}\big(f_{_{I}}(\mathrm{x})~,~f_{_{T}}(t_i)\big)
$$
Prompt Learning
ZeroShot inference in VLMs requires hand-crafted text prompts for each class label. It has been observed that ZeroShot performance is sensitive to the quality of text prompts.
Prompt Learning aims to learn these text prompts from the training data, avoiding the need for manual crafting. Many methods have been introduced for prompt learning for VLMs, but the first prominent method is
COOP which learns the
context of text prompts in the token-embedding space in few-shot setup. Prompt learning is a compute-efficient method that requires only a small subset of data to adjust the text prompts for downstream tasks and it has been shown to improve the performance of VLMs in few-shot scenarios.
BAPLe
Prompt learning is a crucial component in our proposed method
BAPLe. It employs a prompt learning setup that integrates a small set of learnable prompt token embeddings, \(\mathcal{P}\), with class names, forming class-specific inputs \(\mathrm{t}=\{t_1, t_2, \dots, t_C\}\) where \(t_i = \{\mathcal{P}, y_i\}\). Denoting the model's prediction scores on clean image with \(f_{\theta}(\mathrm{x})\in\mathbb{R}^{C}\):
$$
f_{\theta}(\mathrm{x}) = \{~\mathtt{sim}(~f_{{I}}(\mathrm{x})~,~f{_{T}}(t_i)~)~\}_{i=1}^{C},
$$
where \(\mathtt{sim}(\cdot)\) is cosine-similarity function. BAPLe optimizes the following objective function:
$$
\begin{gather}
\underset{ \mathcal{P}~,~\delta }{\mathbf{minimize}}~~ \sum_{(\mathrm{x},y)\in\mathcal{D}_c} \lambda_c \cdot\mathcal{L}\big(f_{\theta}(\mathrm{x}),y\big) ~~+ \sum_{(\mathrm{x},y)\in\mathcal{D}_p} \lambda_p \cdot\mathcal{L}\big(f_{\theta}(\mathcal{B}(\mathrm{x})),\eta(y)\big),\nonumber \\
\mathbf{s.t.}~~~\|\delta\|_{{_{\infty}}} \le \epsilon,~~~~ \mathcal{B}(\mathrm{x}) = (\mathrm{x}+\delta)\oplus\mathrm{p}, \nonumber
\end{gather}
$$
where \(\delta\) represents the imperceptible backdoor trigger noise, \(\epsilon\) is perturbation budget, \(\mathrm{p}\) is the backdoor patch that can be a logo or symbol, \(\mathcal{B}\) the backdoor injection function, and \(\oplus\) represents an operation that combines the original image with the backdoor patch trigger. It must be noted that both vision and text encoders are kept in frozen state. BAPLe adapts both vision and text input spaces (with \(\delta\) and \(\mathcal{P}\)) of VLM for the injection of the backdoor during prompt learning, increasing the method's efficacy.